仮想通貨高頻度取引ロジックが勝てないのは指標の影響なのか?
かの有名botterであるrichmanbtcさんが
仮想通貨自動売買ボットで儲ける方法5: 機械学習ボット|richmanbtc
で言及していた、
重要なのは以下の構造にして、yの予測精度の問題に帰着すること。
バリデーション: バックテスト成績が上がる、ならば、汎化性能(実戦成績)も上がる
yとポジション計算: yの予測精度が上がる、ならば、バックテスト成績が上がる
ということについて記事を書いていきます。
モチベーション
UKIさんの記事などにより、高頻度取引*1においては、価格予測を高い精度(リターンと指標の相関係数 > 0.05)で行うことができれば利益をあげられることは周知されましたが、MakerTakerモデルを採用している取引所でMarket Makingを行う場合指値の性質上不利約定がしやすく、成り行き注文などを利用すると手数料負けするなどの問題があります。
これらの問題などにより、優秀な指標を使ってうまく価格予測ができていたとしても不利約定に負けてしまうようでは、戦略として利益をあげられないことがあります。
今回、私の使っているマーケットメイクロジックが勝てない理由は執行戦略によるものなのではないかと考えたので、それについて検証していきます。
実験
実験1 完璧に価格予測できた場合 (simple)
一般的なロジックを用いても、100%*2の精度で未来の価格を予測できるようであれば、利益をあげられることを確認していきます。
バックテストする際の損益計算は自前で書くとほぼ100%バグらせてしまうので、BacktestAssistantを使って検証していきます。
使うロジックは
でのlinearを用いて発注サイズを調整しつつ、予測した(リークさせた)未来リターンを使って未来価格(futureprice)を算出したのち、現在の価格をpriceとして、
であれば売り指値を発注、
であれば買い指値を発注 するロジックです。
改変した点としては、
検証データは2021/03/14のbybitのBTCUSDデータを使いました。
結果1
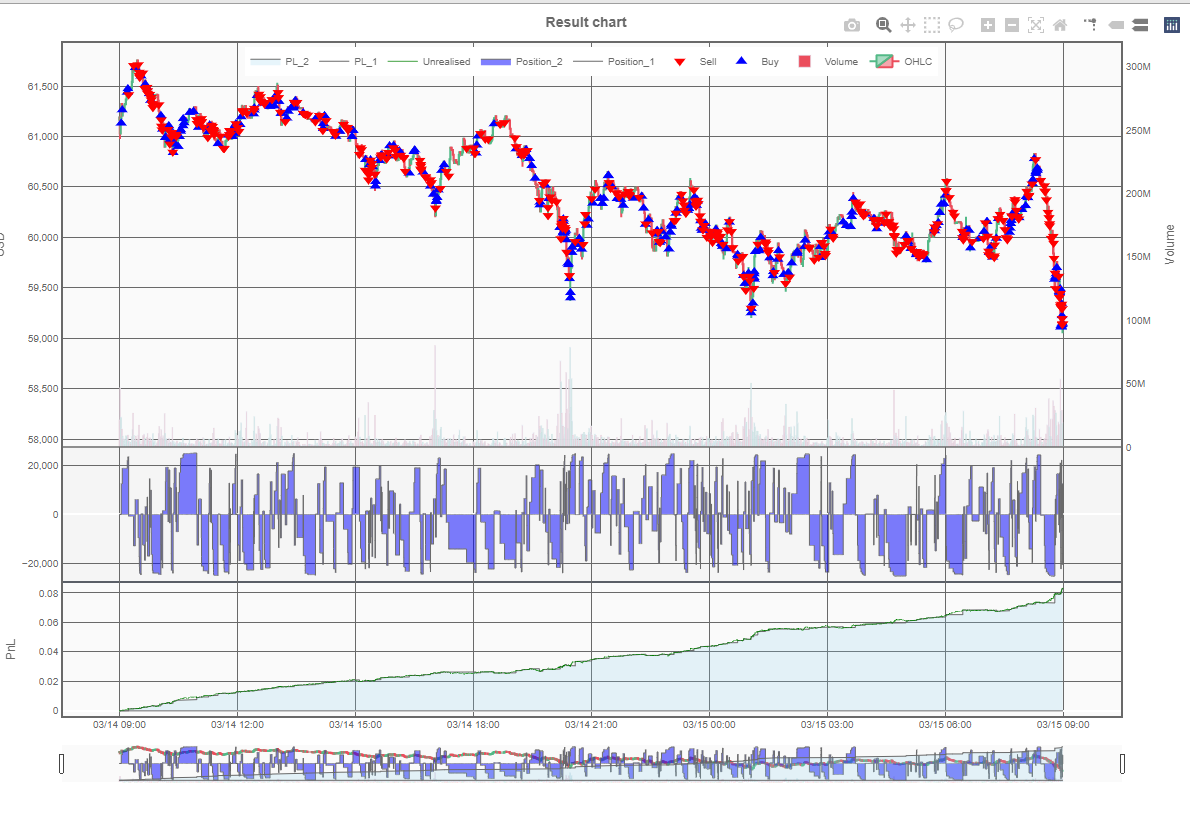

想定のように、価格予測が100%正確にできていれば*3指値注文を使ったロジックでも利益をあげられることがわかりました。
しかし、現実においては未来の価格を予想することは簡単ではありません。
そこで、未来のリターンにノイズを載せたデータを使って同じストラテジーでバックテストすることを考えてみます。
実験2 未来リターンにノイズが載った場合
具体的には、リターンの標準偏差の10倍の標準偏差を持つ平均が0の正規分布に従うノイズを付加することにします。
指標 (未来リターン + ノイズ) と リターンの散布図(上図)はこうなります。
下図は指標のヒストグラムです。

指標とリターンの相関係数は 0.1程度と比較的高く、十分実用的な指標のはずです。
このノイズが載った指標から未来リターンを推測するには、何らかの方法を取る必要がありますが、今回はノイズが載っているので、RANSACRegressorを使います。
しかし、この指標を使って先ほどと同じストラテジーをバックテストすると、きれいに右肩下がりになってしまいます。
結果2


この結果から、相関係数が0.1あるからといって、雑な執行戦略を採用していると余裕で焼かれることがわかりました。
さて、良い執行戦略とは何でしょうか?
(続きをいつか書きます)
積の和典型を形式的べき級数(FPS)で考える
積の和典型の問題設定
問題設定は
積の和典型 - ei1333の日記がわかりやすいです。
長さが、総和が
の非負整数からなる数列の総積の和を求める問題です。
数え上げと対応させて考える方法が他のサイトで紹介されています。
参考:積の和典型 - Shirotsume の日記,
積の和典型 - ei1333の日記
BTCMEXが公式に用意しているPython用WebSocketコネクタがなんかおかしい?話
仮想通貨取引所であるBTCMEX*1用のbotを開発している際に使おうとしていた WebSocketコネクタが,なにかおかしい様なので記事にしてみました.
目次:

おかしい?こと
無限にwaiting
そのままコピペして公式コネクタを使おうとすると,182行目の __wait_for_symbol関数で待ったまま一生を過ごしてしまいます.
というのも, __wait_for_symbol関数は"instrument" , "trade", "quote"トピックのデータが来るまで待ち続けますが,そもそも"quote"トピックはサブスクライブされていないためデータが送られてくることはありません.

実際にトピックをサブスクライブする部分の処理を見ると, サブスクライブしているトピックは"instrument", "order", "ordeBookL2", "trade", "liquidation"のみで "quote"トピックはサブスクライブされてないことがわかります.
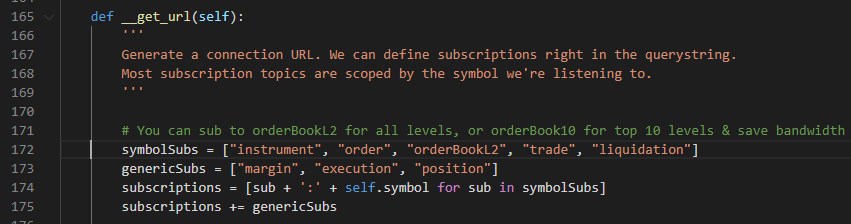
172行目を変更して"quote"を追加することで無限ループから開放されます.

KeyError: "instrument"
ときには KeyError: "quote" として現れることもあります.
標準出力に出てくるのが鬱陶しいですが,出るのは最初の数回のみなので今回は無視することにします.
Partialが来る前にUpdateなどが来ることによって発生します.
open_orders関数が機能しない
そのままです. 機能してくれません.
新規orderに関するデータがupdateトピックを通して送られてきますが,当然同じorderIDを持つ注文に関するデータはないため,updateするものが見つからずバグってしまいます.
(245行目でreturn してしまう)
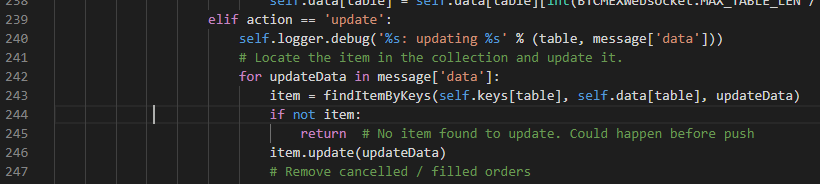
そこで,updateでデータが送られてきた場合にも,トピックが"order"の場合いい感じにデータを挿入するようにしてみます.
242行目から249行目を以下のように変更します
for updateData in message['data']: item = findItemByKeys(self.keys[table], self.data[table], updateData) if not item: if table == "order": self.data[table] += message["data"] # insert order data self.keys[table] = ["orderID"] # self.keys["order"] should be ["orderID"] return # No item found to update. Could happen before push item.update(updateData)
これによって,正しくorderの情報を更新/保持 するようになりました!
キャンセルされたOrderのデータも持っているのが気に食わない
これは宗教かもしれないですが,open_orders("null")を呼んでいるのにopenでないorderのデータが来るのはおかしい気がします.
254行目のremoveする条件が甘いです. サイズが0になる以外にも orderがRejectされたりCancelされる場合があるはずです.

254行目を
if table == 'order' and (not order_leaves_quantity(item) or not item["ordStatus"] in ("New", "PartiallyFilled")):
とすると,本当にOpenでないデータが帰ってくることはなくなります.
これで大部分の人の希望が叶ったのではないでしょうか?
おわりに
あとは各自自由に煮るなり焼くなり好きにしてください.
私の場合はopen_ordersのprefixがNoneの場合はopen_orderを全て返すように変更してみました

これで僕にとっての”いいかんじ”なwebsocketコネクタを作ることができました!
*1:巷ではパチMEXとも呼ばれている
JOI 2012 C - 夜店 【Python/C++で解説】
情報オリンピック2012/2013の本戦での3問目の「夜店」を解説を読みながらACすることができたので,自分なりの解説を残しておこうと思います.
問題リンク:
問題概要
個の夜店があり,インデックスが小さい順に遊んでいく.
各夜店には遊ぶと得られる楽しさと遊ぶのに必要な時間
が設定されている.
JOIくんは時刻から時刻
までの間に夜店をめぐる.
しかし,時刻Sには大きな花火があがるので遊ばないでおく.
JOIくんが実現できる楽しさの和の最大値を求めよ.
重要な制約
考察
まず簡単な全探索を考えます.
各店を遊ぶ/遊ばないの2通りを決めて,条件を満たすかを調べていくと全探索が可能です.
このアルゴリズムの計算量は なので
の場合の部分点(10点) を得ることができます.
ここで問題文をよく見ると,時刻 までの最大の楽しさは,
dp[i+1][j] := 店iまで見て,時刻jまでに実現できる最大の楽しさの和
とすることでで求められることがわかります.*1
時刻までの答えは簡単に求められることがわかったので,時刻
から時刻
までの解を求めることを考えます.
上のDPテーブル上で時刻から
までの答えを考えるときには,普通にナップサックするだけでは答えが求められません(どこの店まで訪れたかわからないため).
新たなDPテーブルとしてdp2を dp2[i][j] := 時刻 から店 i~Nを訪れたときに実現できる最大の楽しさの和 とします.
そうすることによって,答えをdp[i+1][S] + dp2[i][S]とすることができます.
ここで,遷移を考えます.普段のナップサックではdp[0][0]で選択肢が最小ですが,dp2テーブルの遷移はdp2[N][T]が一番選択肢が少なく, dp2[0][S]が一番多い選択肢を持ちます.
DPの遷移でmaxを使う特性上,選択肢が多い方から少ない方へ遷移することは難しく,今回は選択肢が少ない方から多い方へ遷移することにします.
すると,遷移は
のとき dp2[i-1][j] = max(dp2[i-1][j] , dp2[i][j+B[i-1]] + A[i-1])
そうでないとき dp2[i-1][j] = dp2[i-1][j]としてDPテーブルを更新することができます.
よって答えは dp[i][S] + dp2[i+1][S]の和の最大値となります.
実装
*1:これがわからない場合,「ナップサックDP」などで検索してみるといいでしょう
BybitのBTC, ETH, EOS, XRPの変動係数を比べてみる
モチベーション
最近BTC/USD成り行き注文を利用する高頻度取引botを開発していたのですが,ある程度の説明力のある指標を用いても,それをTake戦略で使用すると,成り行き手数料0.075%が重くのしかかってきます.
なので,BTC/USD以外にTake戦略が有利に働くような市場を探します.
今回は,8/1の約定履歴をもとにして作った一秒足のリターンの変動係数(標準偏差 / 平均値)が高ければ高いほど,ボラティリティが高く,成り行きが有利である*1として検証をすすめていきます.
データの用意
bybitの約定履歴は,https://public.bybit.com/trading/ に落ちていますので,それをダウンロードするスクリプトを書いてあとからでも参照しやすくしておきます.
import gzip
import os
import pandas as pd
from datetime import datetime, timedelta
from urllib import request
from time import sleep
#参考: https://qiita.com/yuukiclass/items/88e9ac6c5a3b5ab56cc4
def main():
baseurl = 'https://public.bybit.com/trading/'
#https://public.bybit.com/trading/BTCUSD/BTCUSD2020-05-25.csv.gz
is_concat = input("do you want to concat many days ? (y/n): ")
if is_concat == "y":
start_date, end_date, symbol = input("yyyy-mm-dd(start) yyyy-mm-dd(end) symbol\n").split()
file_title = f"exec_bybit-{start_date}-{end_date}.csv"
df = pd.DataFrame()
start = datetime.strptime(start_date, "%Y-%m-%d")
end = datetime.strptime(end_date, "%Y-%m-%d")
# https://thr3a.hatenablog.com/entry/20180813/1534124783
for i in range((end - start).days + 1):
date_str = start + timedelta(i)
date_str = date_str.strftime("%Y-%m-%d")
filepath = f"{date_str}.csv"
dlurl = baseurl + f"{symbol}/{symbol}{date_str}.csv.gz"
df2 = download(dlurl, filepath)
df = pd.concat([df,df2])
print(f"donwloaded {date_str}")
sleep(0.5)
df.to_csv(file_title)
else:
date, symbol= input('yyyy-mm-dd symbol\n').split()
print('Downloading... ' + baseurl + f"{symbol}/{symbol}{date}.csv.gz")
filepath = f"{date}.csv.gz"
df = download(baseurl + f"{symbol}/{symbol}{date}.csv.gz", filepath)
print('Done!')
file_title = f"exec_bybit-{date}.csv"
df.to_csv(file_title)
print("Done!")
return
def download(url, filepath):
request.urlretrieve(url, filepath)
df = unzip(filepath)
os.remove(filepath)
return df
def unzip(filepath):
with gzip.open(filepath, 'rt') as f:
df = pd.read_csv(f)
return df
if __name__ == "__main__":
main()
また,秒足にする関数も書いておきます.
def makeCandles(df, sec): # 参考: https://note.com/nagi7692/n/ne674d117d1b6?magazine_key=m0b2a506bf904 df.drop(['tickDirection', 'trdMatchID', 'grossValue', 'homeNotional', 'foreignNotional'], axis=1, inplace=True) #86400本の秒足ができるように0秒に約定を入れる df = df.sort_index() df['timestamp'] = pd.to_datetime(df['timestamp'], unit="s") df = df.rename(columns={'timestamp': 'exec_date'}) df = df.set_index('exec_date') df['buy_size'] = df['size'].where(df['side'] == 'Buy', 0) df['buy_flag'] = df['side'] == 'Buy' df['sell_size'] = df['size'].where(df['side'] == 'Sell', 0) df['sell_flag'] = df['side'] == 'Sell' df_ohlcv = df.resample('{}S'.format(sec)).agg({"price": "ohlc", "size": "sum", "buy_size": "sum", "buy_flag": "sum", "sell_size": "sum", "sell_flag": "sum", }) df_ohlcv.columns = ['open', 'high', 'low', 'close', 'volume', 'buy_vol', 'buy_num', 'sell_vol', 'sell_num'] df_ohlcv['buy_num'] = df_ohlcv['buy_num'].astype(int) df_ohlcv['sell_num'] = df_ohlcv['sell_num'].astype(int) df_ohlcv.ffill(inplace=True) return df_ohlcv
実際に見てみる
結果としては,リターンの変動係数の大きい順に並べると, EOSUSD > XRPUSD > BTCUSD > ETHUSDという順になりました.

EOSUSDをbybitで取引する場合には,EOS現物が必要となるので,そういった参入障壁によってリターンのばらつきが生まれているのでしょうか.
BTCUSDよりもETHUSDのほうが変動係数が小さいというのは意外でした. なぜなのでしょうか?
ぜひこれからの取引にこの情報を活用してみてください.
おわりに
今回の記事でつかったJupyterNotebookはGithubに乗せてあります.
また,よければこちらからbybitへの登録をお願いします.
*1:実際はスプレッドが広がっていることが想像される
【ファイナンス機械学習】ビットコインの価格の分数次差分を取ってみる【機械学習】
この記事では,分数次差分を取ったBTCの価格データを作成する方法について紹介しています.

モチベーション
価格の時系列データは低いシグナルノイズ比を示すことが知られている. 加えて,整数次差分のようにデータを定常時系列に変換するための標準的な手法は, メモリー(時系列の平均値を時間経過に従ってシフトさせる過去の水準の長期履歴)を取り除くことでさらにシグナルを弱めてしまうことになる. 一方,リターンのように整数次差分をとった時系列は,有限のサンプル期間外の履歴がすべて無視されているという意味で,メモリーが除去されている.
と書いてある.
BTCの値動きの差分を取ることで,データを定常時系列に変換することがあるが,それは原系列が持ってる長期的な記憶を消していることになっているそうだ.
さらに,
もし,特徴量が定常でなければ,新しい観測値をたくさんの既知の学習データへとマッピングすることができない. しかし,定常性は予測力を保証しない. 定常性は機械学習アルゴリズムが高いパフォーマンスをあげるための必要条件であるが,十分条件ではない. 問題は,定常性とメモリーのトレードオフが存在することである. 差分をとることで時系列をより定常にすることは常に可能であるが,その代償として メモリーを消してしまうことになり,予測という機械学習アルゴリズムの目的を損なうことになる.
とある.
そこで,筆者であるMarcos lopez de pradoは,1階差分や2階差分などではなく,分数次差分を取ることによってそのジレンマを解決することができるとしている.
なので,実際にBTCのデータについて分数次差分を取って,機械学習モデルに学習させることによって,学習能力が向上したかを検証したい.
今回の記事では実際に分数次差分をとった系列を作るとこまで行っていく.
使うデータ, ライブラリ
今回はbybitの5月中の約定データから作ったthreshold=50000としたドルバーを用いて,検証していく.
データの作り方については
を参照してほしい.
今回はmlfinlabとstatsmodelsを使っていく.*1
どちらも,下記コマンドを使ってpipからインストールすることができる.*2
pip install mlfinlab
pip install statsmodels
実際にやってみる
データを読み込む.
import pandas as pd import numpy as np # bybitでのthreshold=50000としてサンプリングした5月中のドルバーを読み込む df = pd.read_csv("data/dollar_bybit-2020-05-01-2020-05-31.csv") df = df.drop(columns=["date_time", "Unnamed: 0", "open", "high", "low", "tick_num", "buyTick_num", "sellTick_num", "volume",\ "buy_vol", "sell_vol", "vwap"]) print(df.head())
実際に"close"というcolumnを含んだDataFrameであれば,どんな形式でも問題はない.
close 0 8628.5 1 8628.5 2 8625.5 3 8625.5 4 8625.5
現系列を表示してみる
%matplotlib inline
# 原系列を表示
prices = df.close
prices.plot()

分数次差分を取ってみる
mlfinlabにあるFractionalDifferentiationクラスを使うことで,簡単に分数次差分を計算することができる.
なお,計算コストが重いのか一回の計算に結構な時間がかかるので,CPUへの負荷も考慮した上で行ってほしい.
frac_diff_ffd関数の第2引数dは, 1.0にすることで,一階差分になり,dは小さければ小さいほど原系列の持つメモリーを保持し,定常性を失っていく.
from mlfinlab.features.fracdiff import FractionalDifferentiation fdiff = FractionalDifferentiation() # d = 1.0 d_10 = fdiff.frac_diff_ffd(df, 1) d_10.close.plot()

先程の通り,d=0.0001などに設定すると原系列の持つメモリーを多く保持する.
# d=0.0001 (ほとんど差分を取らない) d_1 = fdiff.frac_diff_ffd(df, 0.0001) d_1.close.plot()

最適なdを探す
ファイナンス機械学習にあるように,パラメータdには大きくすればするほど定常性を持つが,メモリーを失うというトレードオフの関係がある.
(定常性を保ちつつ,できるだけメモリーを大きくしたい.)
そこで,その時系列データが定常であるかどうかを調べることができるADF検定と二分法を用いて適切なdを探していく.*3*4
statsmodelsというパッケージのadfuler関数を使うことでADF検定をすることができ,今回は
有意水準: 0.01
帰無仮説:「FFD系列は非定常である」
対立仮説を「FFD系列は定常である」
としてADF検定を行った. *5
先述の通り,FFD系列を作るfrac_diff関数は結構なマシンパワーが必要なので,クラウドなどの従量課金制のプラットフォームを使ってる場合は注意してほしい.
# 定常性を保ち(ADF検定でP値 > 0.01),最大のメモリーを持つようなd(0.01 ~ 1) を二分法で探索する # d は大きければ大きいほど定常性をもち,メモリーを失うので, 定常性を持つ範囲でメモリーをもたせたい(p > 0.05となるような範囲での最低のdを探す) from statsmodels.tsa.stattools import adfuller eps = 1e-3 ok = 1 ng = 0.0001 mid = (ok+ng)/2 while ok-ng > eps: mid = (ng+ok)/2 d_ = fdiff.frac_diff(df, mid) d_ = d_.fillna(d_.close.mean())["close"].values result = adfuller(d_, maxlag=1, regression="c") p_ = result[1] # 帰無仮説を棄却できない. データは非定常 if p_ > 0.01: ng = mid print(f"ng! mid:{mid} p_value:{p_}") # 帰無仮説を棄却できる. データは定常 else: ok = mid print(f"ok! mid:{mid} p_value:{p_}") print(f"{ng}, {ok}, {mid}, {result}")

今回の結果によると,d=0.05868789062499999でデータは定常になるらしい.
見つけたパラメータで作ったFFD系列を図示してみる
d_005 = fdiff.frac_diff(df, 0.05868789062499999)
d_005.plot()
d=0.05...でFFD系列を作り図示したところ,以下のようになった.

私の目にはこのデータは非定常であるように見えるが,ADF検定によると有意に定常であるらしい.
終わりに
次の記事では,このデータを使って学習させて実際に1次差分をとった場合との比較もしていきたい.
参考文献
*1:別にmlfinlabライブラリを使わずとも、pandasなどで分数次差分は実装できる。これらのやり方はインターネット上にも記事があるし、ファイナンス機械学習でも具体的にかかれている。より具体的には、次差分を計算するには、バックシフトオペレータBについて、
を(適宜打ち切ったりしながら)原系列に作用させればよい。ただ、この記事を書いていた当時はその点を理解していなかったので、ライブラリに頼っている。
*2:mlfinlabについては,anaconda環境でのインストールが推奨されている
*3: ADF検定についてよく知りません. ごめんなさい. 詳しくはwikipedia参照
*4:検定をするのに,何度もパラメータを変えて有意水準を考えることは統計的にどうなのかという指摘については,わかりませんとしか答えられません. ごめんなさい
*5:参考: https://bellcurve.jp/statistics/course/9313.html, https://logics-of-blue.com/time-series-regression/
Bybitのデータでもドルバーを作りたい【複数日対応】
前回の記事 では,BitMEXの約定履歴からドルバーを作るプログラムを作りましたが,今回の記事ではbybitのデータから複数日のドルバーを作るプログラムを作ります.
前回の記事の問題点
そもそも,前回の記事で作ったプログラムは,BitMEX用でしたが,もう日本からBitMEXを使う方法はありません.
また,mlfinlabを使える環境を用意するにはAnacondaが必要で,環境構築が面倒くさくなるという問題点があります.
そして,一番重大な問題として,BitMEXやBybitではBTC/USDの価格で,Bitcoinの価格を表しますが約定履歴でのsizeはUSD建てでの額となります.
つまり,BitMEXの約定履歴からmlfinlabなどのライブラリを使ってドルバーを作ると,実際に出来上がるのはドル二乗バーとなってしまいます.
この問題はmlfinlabを使ってボリュームバーを作ることによって解決することもできますが, 自前で実装することによって,特徴量の追加なども柔軟に行えるため今回は自前で実装することにしました.
しかし,それによる問題点として,mlfinlabを使った場合に比べて遅いというものがありますが,機械学習の学習に費やす時間と比べたらごく短時間のため今回は無視することにします.
実装
import gzip import os import pandas as pd from datetime import datetime, timedelta from time import sleep from urllib import request #参考: https://qiita.com/yuukiclass/items/88e9ac6c5a3b5ab56cc4 def main(): baseurl = 'https://public.bybit.com/trading/' #https://public.bybit.com/trading/BTCUSD/BTCUSD2020-05-25.csv.gz is_concat = input("Do you want to create data for multiple days? (y/n): ") while not (is_concat == "y" or is_concat == "n"): is_concat = input("Do you want to create data for multiple days? (y/n): ") if is_concat == "y": start_date, end_date, symbol, threshold = input("yyyy-mm-dd(start) yyyy-mm-dd(end) symbol threshold\n").split() threshold = int(threshold) file_title = f"dollar_bybit-{start_date}-{end_date}.csv" df = pd.DataFrame() start = datetime.strptime(start_date, "%Y-%m-%d") end = datetime.strptime(end_date, "%Y-%m-%d") # https://thr3a.hatenablog.com/entry/20180813/1534124783 for i in range((end - start).days + 1): date_str = start + timedelta(i) date_str = date_str.strftime("%Y-%m-%d") filepath = f"{date_str}.csv" dlurl = baseurl + f"{symbol}/{symbol}{date_str}.csv.gz" df2 = download(dlurl, filepath) df = pd.concat([df,df2]) print(f"donwloaded {date_str}") sleep(0.5) df_ohlcv = makeCandles(df, symbol) dollar = make_volume_bar(df_ohlcv, threshold=threshold) else: date, symbol, threshold= input('yyyy-mm-dd symbol threshold\n').split() threshold = int(threshold) print('Downloading... ' + baseurl + f"{symbol}/{symbol}{date}.csv.gz") filepath = f"{date}.csv.gz" df = download(baseurl + f"{symbol}/{symbol}{date}.csv.gz", filepath) print('Downloaded execution data.') file_title = f"dollar_bybit-{date}.csv" df_ohlcv = makeCandles(df, symbol) df_ohlcv.to_csv(file_title) print() dollar = make_volume_bar(df_ohlcv, threshold=threshold) dollar.to_csv(file_title) print("Done!") return date, symbol, sec= input('yyyy-mm-dd symbol sec\n').split() sec = int(sec) baseurl = 'https://public.bybit.com/trading/' #https://public.bybit.com/trading/BTCUSD/BTCUSD2020-05-25.csv.gz print('Downloading... ' + baseurl + f"{symbol}/{symbol}{date}.csv.gz") filepath = "'{}.csv.gz'.format(date)" request.urlretrieve(baseurl + f"{symbol}/{symbol}{date}.csv.gz", filepath) print('Making candles...') df = unzip(filepath) df_ohlcv = makeCandles(df, symbol, sec, date) print('Done!') file_title = f"ohlc_bybit-{date}.csv" df_ohlcv.to_csv(file_title) return def makeCandles(df, symbol): # 参考: https://note.com/nagi7692/n/ne674d117d1b6?magazine_key=m0b2a506bf904 df = df.query('symbol == "{}"'.format(symbol)) df.drop(["symbol", 'tickDirection', 'trdMatchID', 'grossValue', 'homeNotional', 'foreignNotional'], axis=1, inplace=True) df = df.sort_values("timestamp") df['timestamp'] = pd.to_datetime(df['timestamp'], unit="s") df = df.rename(columns={'timestamp': 'date_time', "size": "volume"}) df = df.reset_index(drop=True) print(df) return df def download(url, filepath): request.urlretrieve(url, filepath) df = unzip(filepath) os.remove(filepath) return df def unzip(filepath): with gzip.open(filepath, 'rt') as f: df = pd.read_csv(f) return df def make_volume_bar(df, threshold): N = len(df) INF = 1e9 high = -INF low = INF ret_df = pd.DataFrame(columns=["date_time", "open", "high", "low", "close", "tick_num", "buyTick_num", "sellTick_num", "volume" ,"buy_vol", "sell_vol"]) get_default_row = lambda : pd.Series([None for i in range(len(ret_df.columns))], index=ret_df.columns) print(get_default_row()) current_row = get_default_row() dfs = list() date_times = df["date_time"] sides = df["side"].values prices = df["price"].values volumes = df["volume"].values for i in range(N): # 初期化 if i%1000 == 0: print(f"{i}... {i/N * 100}%...") if current_row["date_time"] is None: current_row["date_time"] = date_times.values[i] current_row["open"] = prices[i] current_row["high"] = prices[i] current_row["low"] = prices[i] current_row["tick_num"], current_row["buyTick_num"], current_row["sellTick_num"], current_row["volume"], current_row["buy_vol"], current_row["sell_vol"] = 0,0,0,0,0,0 if df["side"][i] == "Buy": current_row["buy_vol"] += volumes[i] current_row["buyTick_num"] += 1 if df["side"][i] == "Sell": current_row["sell_vol"] += volumes[i] current_row["sellTick_num"] += 1 # 高値, 安値の更新 current_row["high"] = max(current_row["high"], prices[i]) current_row["low"] = min(current_row["low"], prices[i]) current_row["volume"] += volumes[i] current_row["tick_num"] += 1 # リセット処理 if current_row["volume"] >= threshold: current_row["close"] = prices[i] current_row = get_default_row() dfs.append(current_row) #ret_df = ret_df.append(current_row, ignore_index=True) ret_df = pd.DataFrame(dfs, columns=["date_time", "open", "high", "low", "close", "tick_num", "buyTick_num", "sellTick_num", "volume" ,"buy_vol", "sell_vol"]) print(ret_df) return ret_df if __name__ == "__main__": main()
使い方
プログラムを起動すると,Do you want to create data for multiple days?(複数日にわたってデータを作るか?)と訊かれるのでyもしくはnで答えます.

nを選択した場合は,日付, 通貨のシンボル, バー1本分のしきい値をスペース区切りで入力すると,自動でbybitの約定履歴をダウンロードしドルバーを作成します.

yを選択した場合は,始まりの日付, 終わりの日付, 通貨のシンボル, バー1本分のしきい値をスペース区切りで入力すると,同様にドルバーを作成します.
さいごに
前回の記事でも書いたように,時間バーをドルバーにすることで統計的性質が改善することが知られています.